반응형
1. 데이터 저장 방식
- 데이터베이스에서 데이터를 저장하는 방식은 아래와 같이 다양한 방식이 존재한다.
- 그 중 열 ( Column ) 기반 저장 방식과 행 ( Row ) 기반 저장 방식을 비교하여 확인할 수 있다.
- 행 기반 저장 ( Row-based Storage )
- 데이터를 행 단위로 저장하며, 주로 관계형 데이터베이스에서 사용된다.
- MySQL, PostgreSQL, Oracle DB
- 열 기반 저장 ( Columnar Storage )
- 데이터를 컬럼 단위로 저장하여 데이터 분석(OLAP)에 유리하며, 데이터 웨어하우스 및 분석 시스템에 주로 사용된다.
- SAP HANA
- 키-값 저장 ( Key-Value Storage )
- 데이터를 키-값 쌍으로 저장하며, 매우 빠른 읽기 쓰기 성능을 제공하여, 단순 데이터 모델에 사용된다.
- Redis, Amazon Dynamo DB
- 문서 저장 ( Document Storage )
- 데이터를 JSON, XML 등의 문서의 형식으로 저장하기 때문에 복잡한 데이터 구조를 쉽게 저장하는데 사용된다.
- Mongo DB, Firebase Firestore
- 객체 저장 ( Object Storage )
- 데이터를 객체 단위로 저장하여, 대규모 비정형 데이터를 저장하고 관리하는데 사용된다.
- Amazon S4, Google Cloud Storage, Azure Blob Storage
- 행 기반 저장 ( Row-based Storage )
2. 행 기반 저장 ( Row-based Storage )

- 행 기반 저장에서는 각 행의 모든 컬럽 값을 연속으로 저장한다.
- Row 1 : [1, 홍길동, 인사, 5000]
- Row 2 : [2, 이몽룡, 전산, 6000]
- Row 3 : [3, 김철수, 재무, 5000]
- Row 4 : [4, 김영희, 전산, 6600]
- 행 단위로 데이터를 읽고 쓰기 때문에 새로운 행을 삽입하거나 트랜잭션(OLTP)에 유리하다.
- 하지만, 특정 칼럼의 데이터를 추출할 때는 모든 행의 데이터를 읽어야 하기 때문에 비효율적일 수 있다.
3. 열 기반 저장 ( Columnar Storage )
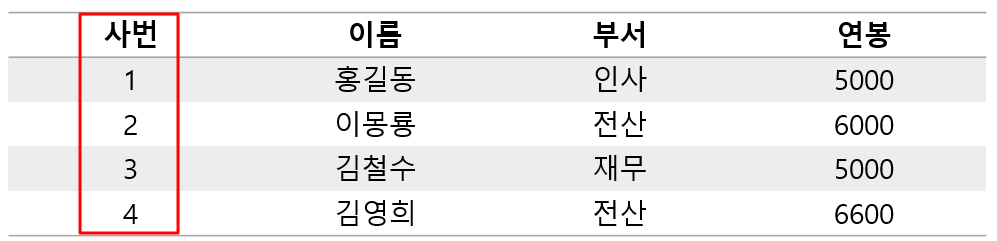
- 열 기반 저장은 각 컬럼의 값을 연속으로 저장한다.
- Column 사번 : [1, 2, 3, 4]
- Column 이름 : [홍길동, 이몽룡, 김철수, 김영희]
- Column 부서 : [인사, 전산, 재무, 전산]
- Coumn 연봉 : [5000, 6000, 5000, 6000]
- 이 방식은 특정 컬럼의 데이터를 읽거나 쓸 때 매우 효율적이며, 특정 컬럼에 대한 집계를 수행할 때와 같은 작업을 하면 성능이 크게 향상된다.
- 또한, 동일한 컬럼의 데이터는 유사한 값을 가지므로, 컬럼 단위로 데이터를 압축 시 높은 압축률을 얻을 수 있으며, 각 컬럼을 독립적으로 병렬 처리 할 수 있다.
- 반면, 행 기반 데이터 삽입 및 갱신과 같은 트랜잭션 처리(OLTP)에는 적합하지 않기 때문에 빈번한 데이터 변경이 발생하는 경우 비효율 적이다.
4. 행 기반 압축
- Oracle DB를 기준으로 행 기반 압축에 대해 설명하면 아래와 같다.
- 기본 테이블 압축 (Basic Table Compression)
- 기본 테이블 압축은 데이터가 처음 압축될 때, 주로 중복된 데이터를 제거하여 데이터 블록 내에 효율적으로 저장될 수 있도록 한다.
- 아래와 같은 테이블에 동일한 값이 여러 번 반복되는 경우, 하나의 값은 저장하고 반복되는 값은 참조를 통해 테이터를 관리한다.
[ 데이터가 처음 삽입된 상태 ]

[ 삽입 후 데이터가 압축된 상태 ]

[ 데이터 변경 후 : Row 2의 급여를 5000으로 변경 -> 압축 X ]

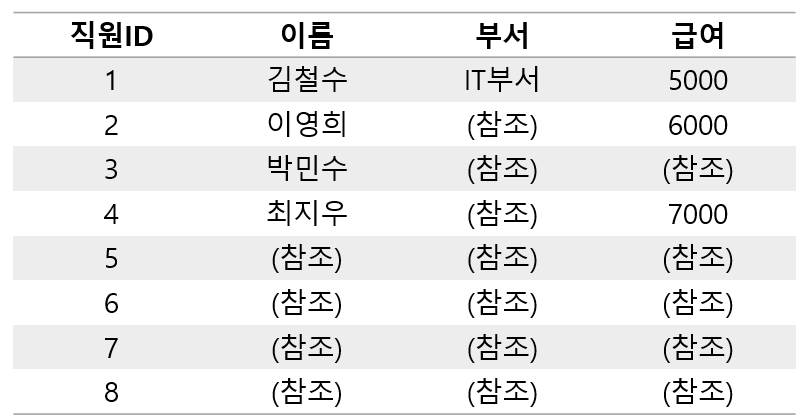
- 고급 행 압축 (Advanced Row Compression)
- 기본 테이블 압축은 데이터가 처음 압축될 때, 주로 중복된 데이터를 제거하여 데이터 블록 내에 효율적으로 저장될 수 있도록 한다.
- 아래와 같은 테이블에 동일한 값이 여러 번 반복되는 경우, 하나의 값은 저장하고 반복되는 값은 참조를 통해 테이터를 관리한다.
[ 데이터가 처음 삽입된 상태 ]

[ 삽입 후 데이터가 압축된 상태 ]
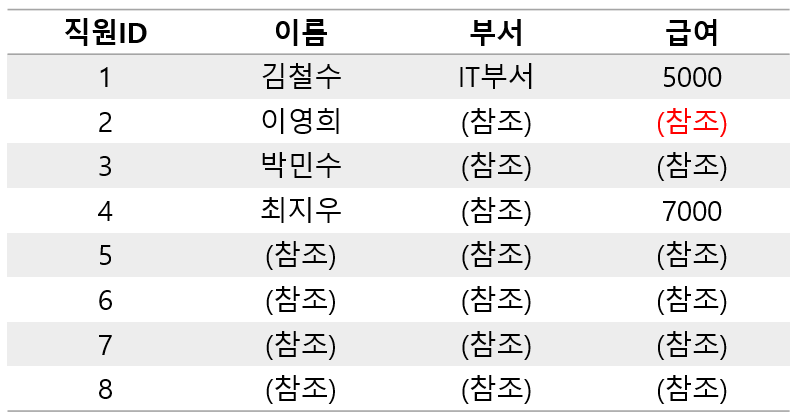
[ 데이터 변경 후 : Row 2의 급여를 5000으로 변경 - 압축 O ]
5. 열 기반 압축
- HANA DB를 기준으로 행 기반 압축에 대해 설명하면 아래와 같다.
- 예제 테이블은 아래와 같으며, 열 기반 저장에서 설명한 것 처럼 데이터는 아래와 같이 저장된다.
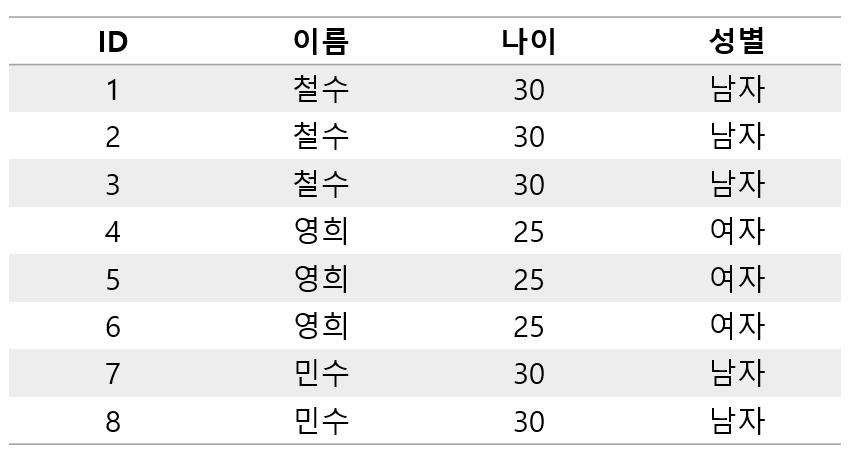
- 열 기반에서는 같은 열을 연속으로 저장한다.
- Column ID : [1, 2, 3, 4, 5, 6, 7, 8]
- Column 이름 : [철수, 철수, 철수, 영희, 영희, 영희, 민수, 민수]
- Column 나이 : [30, 30, 30, 25, 25, 25, 30, 30]
- Column 성별 : [남자, 남자, 남자, 여자, 여자, 여자, 남자, 남자]
1) Run-Length Encoding (RLE)
- 동일한 값이 연속적으로 나타나는 경우 이를 압축하는 기법이다.
- 따라서, 각 칼럼을 아래와 같이 압축 할 수 있다.
- "이름" 열 압축 : 철수 (3), 영희 (3), 민수 (2)
- "나이" 열 압축 : 30 (3), 25 (3), 30 (2)
- "성별" 열 압축 : 남자 (3), 여자 (3), 남자 (2)
2) Dictonary Encoding
- Dictionary Encoding은 고유한 값들을 사전에 저장하고, 각 값에 대한 인덱스를 저장하는 기법이다.
- "이름" 열의 값 들을 사전에 저장하고, 각 값에 대한 인덱스를 저장
- Dictonary : {1: 철수, 2: 영희, 3: 민수 }
- Encoded : 1, 1, 1, 2, 2, 2, 3, 3
- "성별" 열의 값 들을 사전에 저장하고, 각 값에 대한 인덱스를 저장
- Dictionary : {1: 남자, 2: 여자}
- Encoded : 1, 1, 1, 2, 2, 2, 1, 1
- SAP HANA는 인코딩 기법을 사용하여 데이터를 처리하는데 이러한 인코딩 기법이 데이터의 크기를 줄이는데 역할을 하고, 결과적으로 압축의 효과를 가져온다.
- 따라서, Run-Length Encoding과 Dictionary Encoding도 데이터 압축의 일환으로 불 수 있다.
반응형
'Infra > Database' 카테고리의 다른 글
| # [Database] HANA DB vs Oracle DB (2) | 2024.11.01 |
|---|---|
| # [Database] OLTP와 OLAP (0) | 2023.11.08 |